
Okay, my first note (in English) here. Not unlikely the first. But I won’t spend much time polishing, proofreading (and I won’t use chatgpt for that), so take it for what it is.
This first note is about my first real attempt to start a project using duckdb (in R) instead of using Stata or R (data.table or tidy) for preparing the data. I’ll only share a glimpse of what I did, but maybe it is enough for you to get started.
Case and starting point: merging two datasets in Stata.
So for this project I needed to merge two datasets. One has about 4million observations and the other one about 31million observations. Not massive, but also not small. A small benspænd (Danish word for hurdle or obstacle, but these translations are not getting the real meaning of the Danish term) is that I need to condition on a few things and merge with a third (tiny) dataset required for the conditioning. So for the Stata users, this is what I did in Stata:
// Stata example of loading and merging data
// Last edited 2025-07-10 by hhs
clear
// First create an aggregated kotre dataset
// Load kotre
use ELEV3_VTIL audd pnr using $kotre_path,clear
// Merge to audd
merge m:1 audd using "$audd_path", keep(1 3) nogen
// Keep if within 2015
keep if year(ELEV3_VTIL)<2015
// Only codes up to 71
keep if code<71
// Max
collapse schooling=code, by(pnr)
// Save
save "temp.dta",replace
// Now load grundvive and merge on
use pnr FAR_ID MOR_ID using $grundvive_path,clear
// merge to mother
rename pnr tempvar
rename MOR_ID pnr
merge m:1 pnr using "temp.dta", nogen keep(1 3)
rename schooling mother_schooling
drop pnr
// merge to father
rename FAR_ID pnr
merge m:1 pnr using "temp.dta", nogen keep(1 3)
rename schooling father_schooling
drop pnr
rename tempvar pnr
// Save
save "merged_data.dta",replace
// Cleaning
rm "temp.dta"Could this be done more efficient? Not unlikely. But I did try a few alternatives to collapse, and this was the fastest. It takes about 30ish seconds to run. I have to admit that was a lot faster than what I expected.
Moving to duckdb in R (and sql)
I know a bit of sql, but it is a bit rusty. And my python is also more rusty than I care to admit, so let me start with moving to duckdb in R (moving slowly). This is what I did in R:
#load libraries
library("duckdb")
library("DBI")
# Open connection
con<-dbConnect(duckdb::duckdb())
# Sql query
df_kotre<-dbGetQuery(con,paste0("
WITH kotre_filtered AS (
SELECT k.pnr, CAST(l.AUDD2015_L1L5_K AS DOUBLE) as educ,
k.ELEV3_VTIL, l.start
FROM read_parquet('",kotre_path,"' ) as k
INNER JOIN read_parquet('",audd_path,"') AS l
ON k.audd=l.start
WHERE educ <71 AND ELEV3_VTIL< DATE '2015-01-01'),
kotre_maxed AS (
SELECT pnr, MAX(educ) AS X_EDUC
FROM kotre_filtered
GROUP BY pnr
)
SELECT child.pnr, mother.X_EDUC as X_EDUC_MOTHER,father.X_EDUC
as X_EDUC_FATHER
FROM read_parquet('",grundvive_path,"') AS child
LEFT JOIN kotre_maxed AS mother ON child.MOR_ID=mother.pnr
LEFT JOIN kotre_maxed AS father ON child.FAR_ID=father.pnr
"))
# Save
save(df_kotre,file="df_kotre.Rdata")
# Close connection
dbDisconnect(con,shutdown=TRUE)
This can certainly also be improved. But it works. And runs in about 10 seconds. Importantly I got there in about 30minutes with some help from chatgpt (and my rusty sql). I simple gave chatgpt my Stata code and asked it to translate it to a duckdb and parquet setting in R. And it works great.
Why moving faster and lighter?
Most of my work is in a shared space on a server. I share disk space, cpu etc. So the lighter and faster I can be, the better for me and others. And another reason is, of course, that if I make a mistake I can fix it quickly.
First step: parquet files, making it lighter
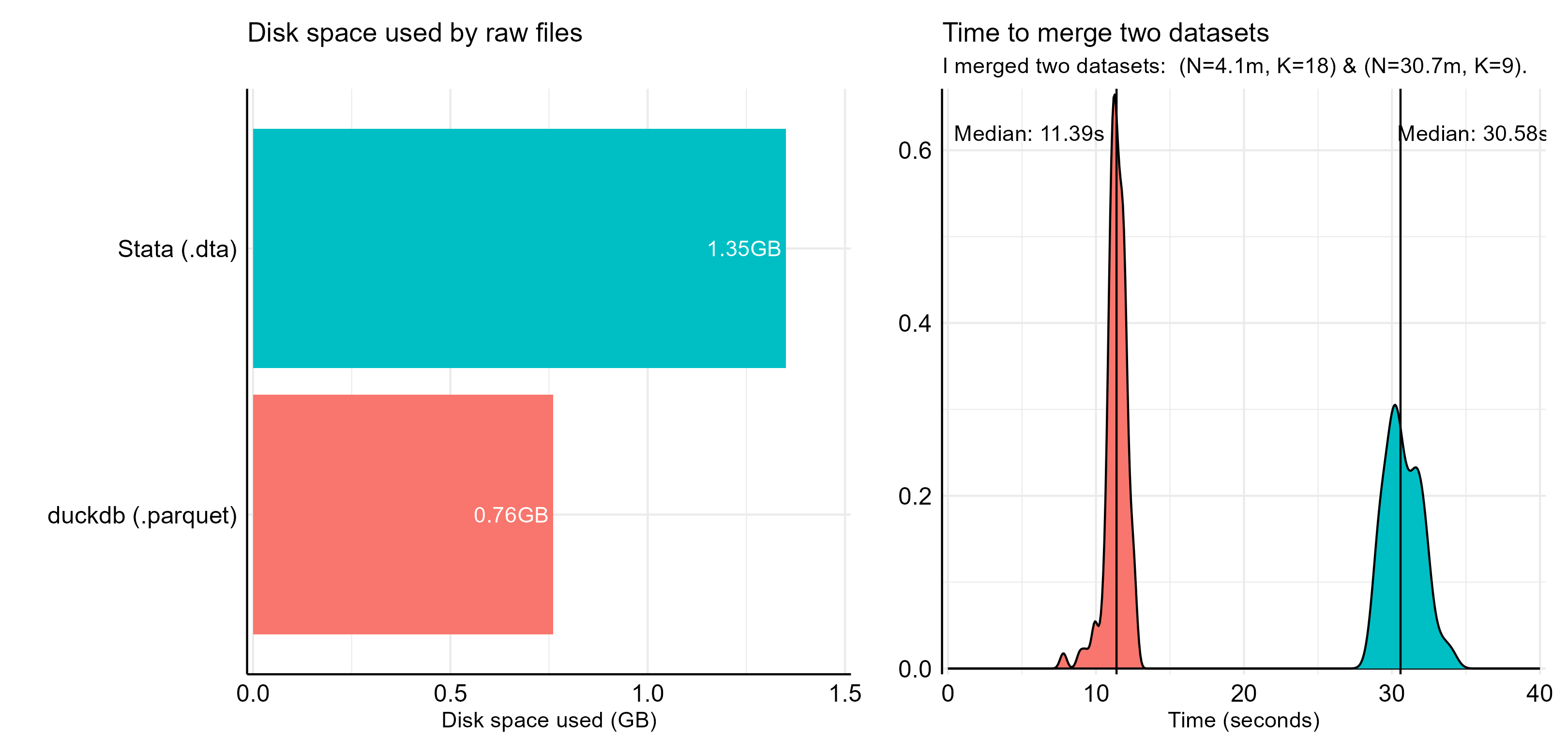
Just moving from dta files to parquet files. That saves quite some space compared to dta files. Take the example above, for example, as the figure below (left) shows, saving the raw files in .parquet format instead of .dta (with compress!!) saves almost 50% of disk space.
And even if you do not care to move to duckdb and sql, you can make parquet work with tidyverse or data.table in R. Arrow in R is great!
Second step: speed
Now let us compare the time it takes to run the Stata and R codes above. The figure to the right above shows the distribution of run times. duckdb in R is about 3 times faster than Stata. I did expect a much bigger difference. But this is my first attempt and the datasets are not massive. Making the duckdb implementation more efficient might make a difference, and dealing with larger (and more efficiently stored?) datasets will also make a difference. I am happy to hear your suggestions (but first of all need to move on with this project).
That is all folks. Hans